Inconsistent Data Sets: Augmentation of the ETL Process for CMS Quality Data
When something occurs automatically, the computer completes a task from start to finish. In an augmented task, the computer helps the person to complete the task, but needs some form of interaction or input from the user.
Previously, we explained how Freedman Analytical Engine (FAE) uses metadata dictionaries to convert column headers and measure identifiers to a normalized, canonical value. Though algorithms can be used to begin this process, such as pulling out column headers with the words “provider” and “id” or “number” in them and assigning “provider_id”, this process is not automatic.
Not all of the synonyms follow a clear, programmable pattern. Allowing for an augmented process means including human decision-making in finding synonyms. Once this dictionary is created, it can be used for all of the CMS quality data files. There is not a new dictionary for each file.
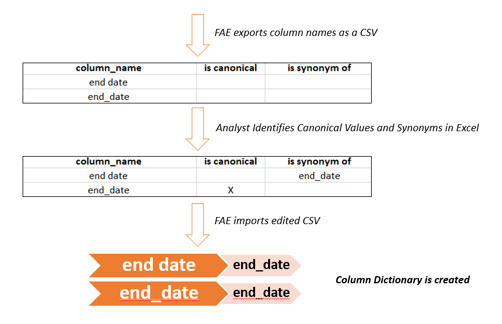
As seen above, FAE exports a list of all distinct column names in the CMS quality data as a CSV. Although some canonical values and synonyms are found automatically by FAE, others must be identified by a human. This updated CSV file is then imported and FAE creates the column dictionary, as we’ve seen previously. This process does not always need a healthcare analyst. A programmer may be able to identify synonyms of column headers. Differentiating between processes that require a healthcare analyst and those that can be completed by a programmer makes this ETL method efficient. An analyst with healthcare data knowledge is needed to build a dictionary of measure identifiers. Two seemingly different measure identifiers may refer to the same healthcare measurement, and different use cases may require different levels of specificity.
Due to these interactive steps, the process of creating the column and measure dictionaries is cyclical. FAE processes data, waits for human input through the form of an imported CSV file, processes that data, waits for more human input, etc. If the data were consistently formatted, this cycle would not need to exist, but because we are normalizing different file formats, column header names, and measure identifiers, both a programmer and analyst must get involved. In order for the data we use to be analyzed, just like APCD data, we need to process it into a merged source.
In the next blog post, we will discuss the five structures we find within the CMS quality data.
New Blog Series: Inconsistent Data Sets
How do you deal with inconsistent data?
Every experienced analyst knows that about 90% of the job is getting your data in shape for analysis. This 90% is not only time-consuming, but also more drudgery than enlightenment. This is especially true if you need to merge multiple data sets and whose file formats are not identical. A classic example are the rich data from CMS’ Hospital Compare. Every quarter, CMS releases updated results. And too often, those updates are formatted differently than their predecessors—changed field names, new data formats, altered data structure, etc. How can a health care analyst spin Hospital Compare gold from the mess of data file straw?
For those who don’t know, Hospital Compare offers extensive quality and other data for dozens of measures, thousands of hospitals, and multiple years. The challenge is how to merge it all when file format may vary from year to year.
In these 6 posts, Hannah Sieber, Software Engineer at FHC, will discuss the challenges and a very real solution that speeds production time, reduces analyst angst, and prevents human errors. See post #1 on ETL Process for CMS Quality Data and post #2 on The Use of Dictionaries for CMS Quality Data ETL.
Although Hannah’s example is Hospital Compare, FHC’s solution will work for all manner of merged data sets: hospital discharge data merged across several states, all-payer claims data (APCD) across multiple years or states; population health data for one provider organization from multiple insurance plans, and many more.
I hope you enjoy the series. If you need help with data tasks like these, please reach out. We’d be glad to help.
-John Freedman, President, Freedman HealthCare