Inconsistent Data Sets: ETL Process for CMS Quality Data
New Blog Series: Inconsistent Data Sets
How do you deal with inconsistent data?
Every experienced analyst knows that about 90% of the job is getting your data in shape for analysis. This 90% is not only time-consuming, but also more drudgery than enlightenment. This is especially true if you need to merge multiple data sets and whose file formats are not identical. A classic example are the rich data from CMS’ Hospital Compare. Every quarter, CMS releases updated results. And too often, those updates are formatted differently than their predecessors—changed field names, new data formats, altered data structure, etc. How can a health care analyst spin Hospital Compare gold from the mess of data file straw?
For those who don’t know, Hospital Compare offers extensive quality and other data for dozens of measures, thousands of hospitals, and multiple years. The challenge is how to merge it all when file format may vary from year to year.
In the next 6 posts, Hannah Sieber, Software Engineer at FHC, will discuss the challenges and a very real solution that speeds production time, reduces analyst angst, and prevents human errors.
Although Hannah’s example is Hospital Compare, FHC’s solution will work for all manner of merged data sets: hospital discharge data merged across several states, all-payer claims data (APCD) across multiple years or states; population health data for one provider organization from multiple insurance plans, and many more.
I hope you enjoy the series. If you need help with data tasks like these, please reach out. We’d be glad to help.
-John Freedman, President, Freedman HealthCare
It’s challenging and time-consuming to transform data into actionable information. Whether it be all payer claims data, a hospital discharge dataset, or, in our case, quality data, organizing and understanding data is complex. To speed up this process, Freedman HealthCare developed the Freedman Analytical Engine (FAE). It’s an ETL tool (extract, transform, load) for public quality data from the Centers for Medicare and Medicaid Services (CMS) for analytic work. FAE helps normalize data across multiple files as a first step in making it ready for analysis.
CMS data is provided as CSV files that come in a variety of structures. Column headers are not consistently named and their placement is not consistent across files. This makes analysis more difficult, as files cannot simply be merged.
It’s important to note that FAE organizes the data in the file. It does not determine if the values in the file are correct. Below is a fabricated example, based on similar challenges I’ve encountered in the CMS files.
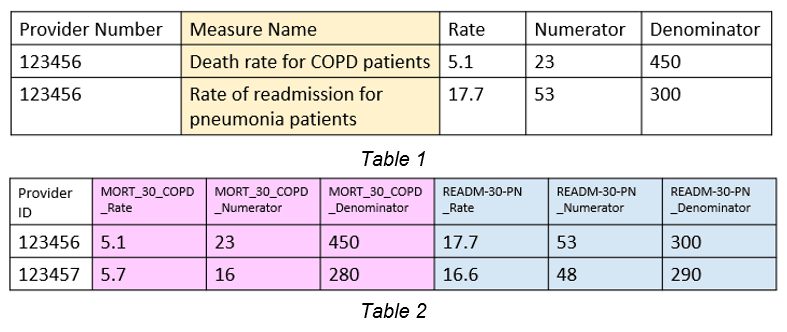
It is apparent that there are inconsistencies with the expression of measures. A measure, in the above cases “Death rate for COPD patients” (MORT_30_COPD) and “Rate of readmission for pneumonia patients” (READM_30_PN), gives context to the data. It answers the question, “What was measured to get this value?”
In Table 1, there is not a clear measure identifier in the form of a code (such as “MORT_30_COPD”) which is used elsewhere. Instead a full name is used. In Table 2, there is more than one distinct measure in a single row (MORT_30_COPD and READM_30_PN), with a group of columns representing one measure’s attributes (numerator and denominator). For an analyst to group and understand data, there needs to be a single column header for each attribute, a single and consistent measure identifier for each row, and a single format for all sets of data. In a future post, all of the file formats used in CMS quality data will be discussed.
FAE combines all possible quality data formats, with generalization possible for future formats, into a single CSV file for analysis. Throughout this series of blog posts we will discuss the data challenges we’ve encountered, our methods to solve them, and, most importantly, tips for applying our lessons learned in your own work. Join us as we explain our technique for making data analysis with CMS quality data feasible and meaningful.
In the next blog post, I will discuss using dictionaries to better perform ETL on the CMS quality data.