Inconsistent Data Sets: The Use of Dictionaries for CMS Quality Data ETL
In the previous blog post, I explained the general ETL process for CMS quality data.
Analysis of quality data from the Centers for Medicare and Medicaid Services (CMS), just like all payer claims data, population health management data, and other data sources, requires the data to be extracted, transformed, and loaded. The majority of this process, known as ETL, is completed by the Freedman Analytical Engine (FAE). This post focuses on the transformation step, in which we normalize or standardize the data format, while considering the fact that column and row orientation, headers, and measure identifiers are all inconsistent from file to file.
In order to normalize column headers and measure identifiers, FAE uses dictionaries. Dictionaries are data structures that allow us to connect multiple synonyms for one canonical or standardized value. Column headers “End_Date”, “Measure End Date”, “FUH_Measure_End_Date”, and “Flu_Season_End_Date” are all synonyms to the canonical value “end_date”. When FAE sees a synonym, the dictionaries make it possible to translate that synonym into its canonical value.
The same type of dictionary is used to normalize measure identifiers. When transforming the data, FAE is able to look up the meaning of these column headers and measure identifiers to standardize the data and create one merged dataset.
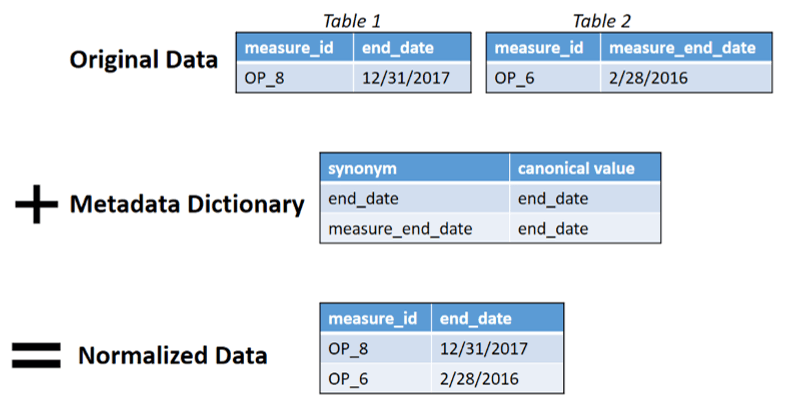
Dictionaries are a form of metadata, data that helps us to explain and process other data. Meta-thinking is when a person thinks about their own thinking patterns. Similarly, metadata is data about data. Dictionaries are metadata in that their purpose is to help normalize and explain the larger dataset. The addition of this metadata dictionary allows FAE to merge multiple tables into one file for analysis. Without dictionaries, in the following example, Excel would not be able to process Table 1 and Table 2 as one dataset because they use different column headers for “end_date”. This is a major step in FAE’s transformation process.
In our next post, we will talk about the difference between automation and augmentation in the ETL process.
New Blog Series: Inconsistent Data Sets
How do you deal with inconsistent data?
Every experienced analyst knows that about 90% of the job is getting your data in shape for analysis. This 90% is not only time-consuming, but also more drudgery than enlightenment. This is especially true if you need to merge multiple data sets and whose file formats are not identical. A classic example are the rich data from CMS’ Hospital Compare. Every quarter, CMS releases updated results. And too often, those updates are formatted differently than their predecessors—changed field names, new data formats, altered data structure, etc. How can a health care analyst spin Hospital Compare gold from the mess of data file straw?
For those who don’t know, Hospital Compare offers extensive quality and other data for dozens of measures, thousands of hospitals, and multiple years. The challenge is how to merge it all when file format may vary from year to year.
In these 6 posts, Hannah Sieber, Software Engineer at FHC, will discuss the challenges and a very real solution that speeds production time, reduces analyst angst, and prevents human errors. See post #1 on ETL Process for CMS Quality Data.
Although Hannah’s example is Hospital Compare, FHC’s solution will work for all manner of merged data sets: hospital discharge data merged across several states, all-payer claims data (APCD) across multiple years or states; population health data for one provider organization from multiple insurance plans, and many more.
I hope you enjoy the series. If you need help with data tasks like these, please reach out. We’d be glad to help.
-John Freedman, President, Freedman HealthCare