Inconsistent Data Sets: The Five CMS Quality Data File Structures
In the last blog post we discussed augmenting the ETL process for CMS quality data. Freedman Analytical Engine (FAE) starts with this quality data, which does not have a consistent structure, and normalizes the column headers and measure identifiers, merging it into one CSV for analysis. To normalize these varying formats, the different file structures must be identified. This post will explore the five structures that we have encountered and the ways in which we categorize them. FAE allows much of this process to be automated and reduces the time needed from an analyst.
Identifying file structures starts with looking at the column headers. We use column headers, as well as our column dictionary, to understand the format of the data. For example, without a provider ID column, or with a provider ID column that contains “nation” as a value, we know we have a Roll Up file. Roll Up files contain aggregated values. They have measure identifiers, but the values are not based on one single provider. Our analysts create their own aggregated values, so these files are not used. File 1 is an illustration of a simplified Roll Up file.

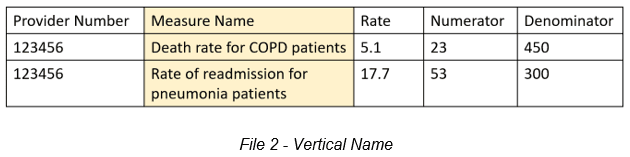
Files that do not contain a column for measure identifiers in the form of codes, but instead list the full name, are known as Vertical Name files. The data is still presented in a vertical fashion, with each row representing one measure for one provider, but there is no column for the normalized measure identifier. File 2 represents a Vertical Name file.
Any file that has more than one measure identifier column is called a Horizontal file. These files have more than one measure in a single row. The following illustration demonstrates a Horizontal file, which has both MORT_30_COPD and READM_30_PN measures in each row.

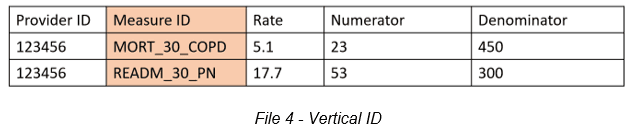
Files that have a measure identifier, with one measure and provider for each row are called Vertical ID files. Transposed files look very similar to Vertical ID files in that they both have a single measure identifier column. Transposed files, however, have multiple rows contributing to the same measure. A series of rows reflects attributes of one single measure, and in that way it appears as a rotated Vertical ID file.
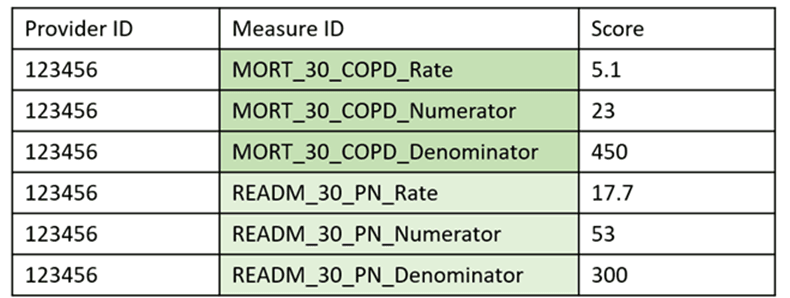
File 5 – Transposed
The images above represent Vertical ID and Transposed files. It is apparent that the column headers are not enough to identify their file types. Instead, FAE must read the values in the Measure ID column and, with the help of a programmer, determine if the values are attributes of one measure (like MORT_30_COPD_Numerator and MORT_30_COPD_Denominator, which are both attributes of MORT_30_COPD) or if they are each a unique measure (like MORT_30_COPD and READM_30_PN). FAE pulls out any files that have patterns similar to this MORT_30_COPD pattern, where the prefix is repeated, and a programmer determines if those files are Transposed.
The process of identifying file formats is almost entirely automated. FAE requires minimal time from an analyst to accurately categorize file structures.
In the next post, we will discuss how we augment the identification of the five file types found in CMS quality data.